Sneaking Syntax into Transformer Language Models with Tree Regularization
Ananjan Nandi1,Christopher Manning1, andShikhar Murty1
1Stanford University
TL;DR: TreeReg is an auxiliary loss term to inject syntactic inductive biases into transformer circuits without architectural modifications, resulting in improved data-efficiency, out-of-distribution language understanding and generalization.

An overview of TreeReg
Abstract
While compositional accounts of human language understanding are based on a hierarchical tree-like process, neural models like transformers lack a direct inductive bias for such tree structures. Introducing syntactic inductive biases could unlock more robust and data-efficient learning in transformer language models (LMs), but existing methods for incorporating such structure greatly restrict models, either limiting their expressivity or increasing inference complexity.
This work instead aims to softly inject syntactic inductive biases into given transformer circuits, through a structured regularizer. We introduce TreeReg, an auxiliary loss function that converts bracketing decisions from silver parses into a set of differentiable orthogonality constraints on vector hidden states. TreeReg integrates seamlessly with the standard LM objective, requiring no architectural changes.
LMs pre-trained with TreeReg on natural language corpora such as WikiText-103 achieve up to 10% lower perplexities on out-of-distribution data and up to 9.5 point improvements in syntactic generalization, requiring less than half the training data to outperform standard LMs. TreeReg still provides gains for pre-trained LLMs: Continued pre-training of Sheared Llama with TreeReg results in improved syntactic generalization, and fine-tuning on MultiNLI with TreeReg mitigates degradation of performance on adversarial NLI benchmarks by 41.2 points.
Method
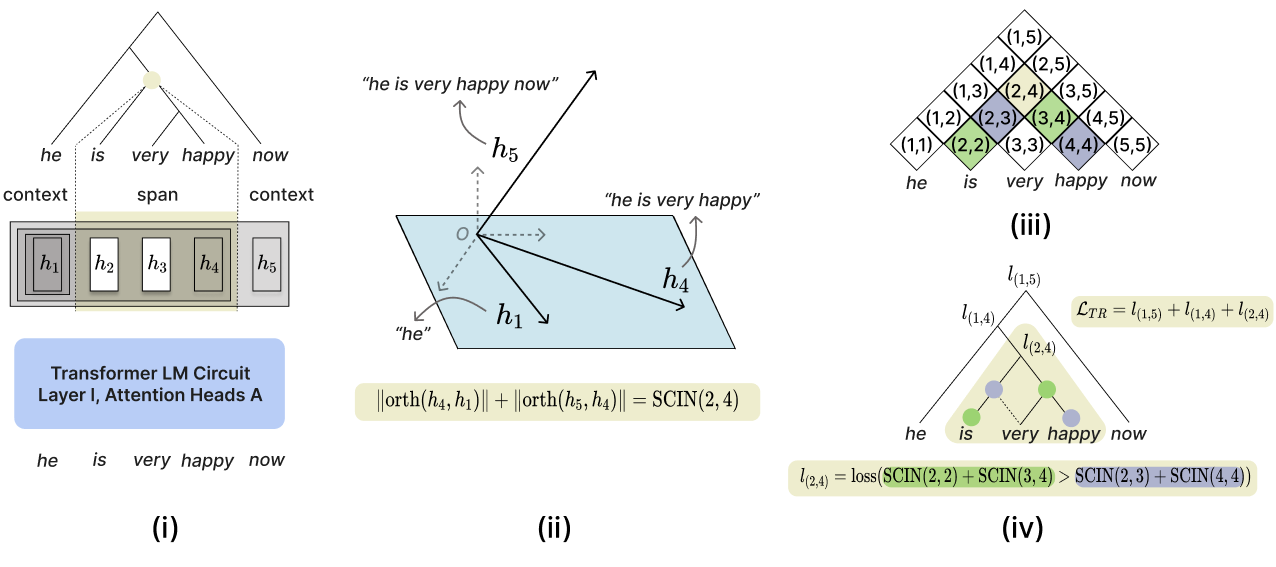
Computation of the TreeReg loss (LTR) for "he is very happy now". This loss term softly biases hidden states from a given transformer circuit to respect syntactic structure through orthogonality constraints.
Key Highlights
- 🛠️Plug-and-Play Regularizer: Just add TreeReg to your LM loss — no changes to model architecture or inference.
- 📈Data-Efficient Language Learning: Outperforms baselines on syntactic generalization with less than half the training data.
- 🚀Robust OOD Understanding: Boost out-of-distribution language understanding and syntactic generalization across model scales.
- 🧩Broad Applicability: Effective during pre-training from scratch, as well as continued pre-training and fine-tuning of pre-trained LLMs.
- 🔄Flexible and Efficient: Apply TreeReg on a parsed dataset while pre-training on a separate unparsed corpus, and retain all benefits.
Overview of Results
Detailed experimental setups and results are available in our paper.
Grokking:
LMs pre-trained with TreeReg grok faster and achieve higher performance than non-syntactic baselines on diagnostic sentence transformation tasks.Model Accuracy (↑) Iteration of Convergence (↓) Tense Inflection Base LM 47.2 ± 16.7 427k ± 41k TreeReg LM 90.4 ± 6.3 391k ± 35k Question Formation Base LM 42.1 ± 15.4 460k ± 7k TreeReg LM 99.6 ± 0.7 43k ± 26k Pre-training on a parsed corpus:
Pre-training 16-layer language models from scratch with TreeReg on the BLLIP-LG corpus results in out-of-distribution language understanding improvements on the Penn Treebank, as well as syntactic generalization gains on BLiMP and SyntaxGym.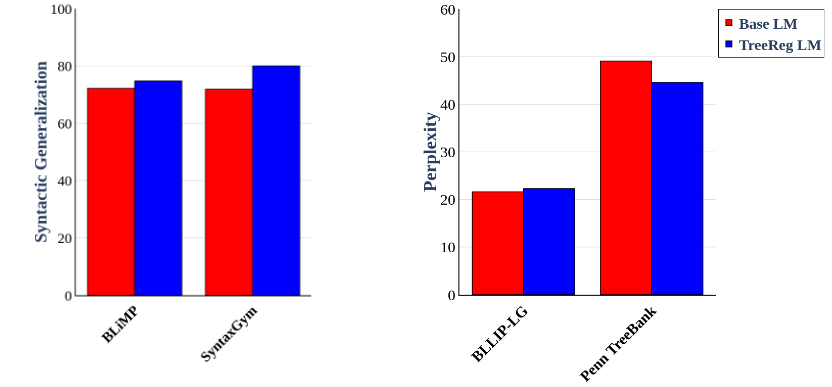
Pre-training sample-efficiency:
Model with TreeReg surpasses the baseline's syntactic generalization when trained on only half of its training data.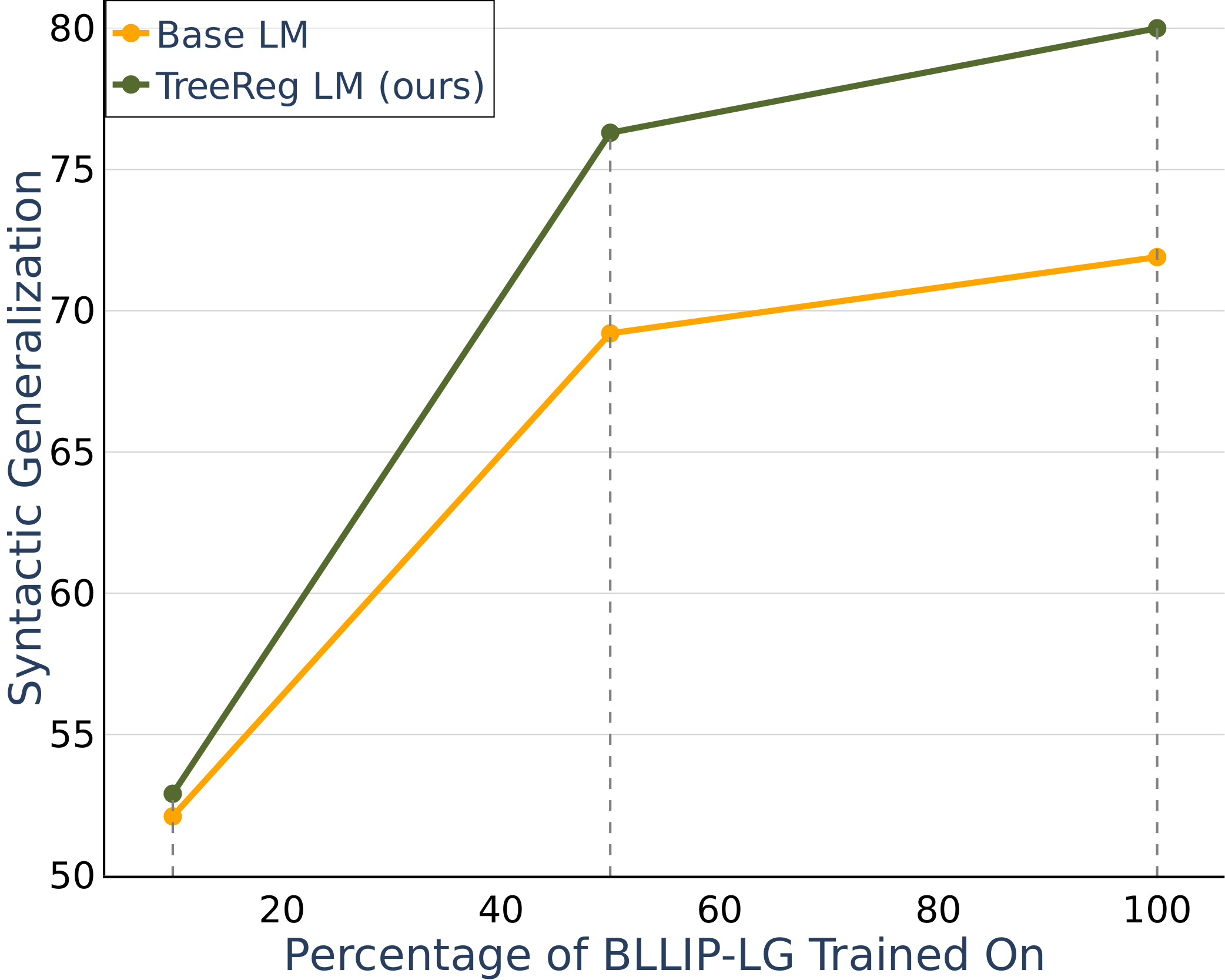
Pre-training on a mixture of parsed and unparsed corpora:
Pre-training GPT-2-small on the unparsed WikiText-103 corpus while performing TreeReg on the parsed BLLIP-LG corpus results in improved syntactic generalization and out-of-distribution language understanding.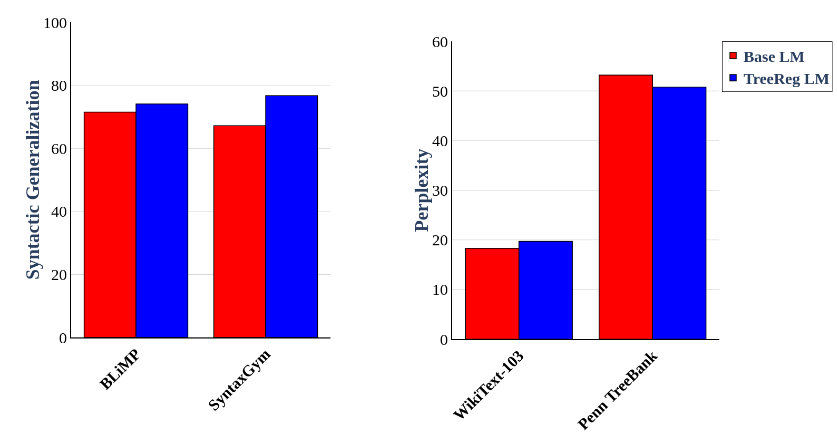
Continued pre-training:
Using TreeReg during continued pre-training of Sheared Llama-1.3B (Base LM) on the BLLIP-LG corpus results in improved syntactic generalization and out-of-distribution language understanding compared to a non-syntactic baseline (CPT LM).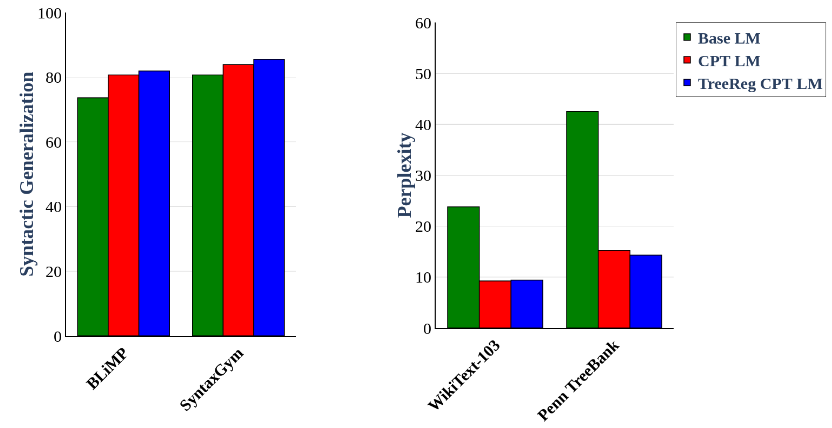
Fine-tuning:
When used during fine-tuning of Sheared-Llama-1.3B on Natural Language Inference datasets, TreeReg mitigates degradation of performance on adversarial benchmarks (MoNLI, MED) compared to a non-syntactic baseline (FT LM).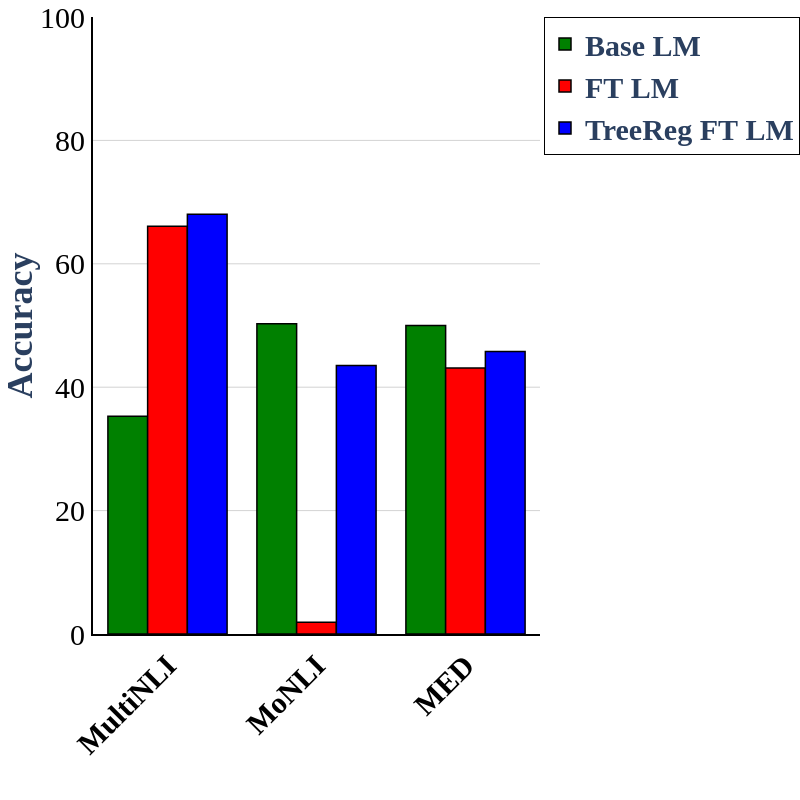
Citation
If you find our work useful, please cite our paper:
@misc{nandi2025sneakingsyntaxtransformerlanguage,
title={Sneaking Syntax into Transformer Language Models with Tree Regularization},
author={Ananjan Nandi and Christopher D. Manning and Shikhar Murty},
year={2025},
eprint={2411.18885},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.18885},
}